What is Retrieval-Augmented Generation (RAG)? -- Part 3: Retrieval

This image is generated by AI (DALL·E 3).
In case of potential copyright infringement, please let me know.
This is the first part of a three-part blog:
In the part one and two of this blog, we discussed two key concepts in RAG:
- Context helps LLMs to produce better response by conditioning on the extra evidence;
- Embedding is a projection from texts to vector representations, such that relevant texts have close distance in the vector space.
In this final part, we will put things together and implement the previous Wikipedia Q&A example.
End-to-end implementation of conversational RAG
A conversational RAG means an AI application will use both documents and chat history to generate responses. In this section, we implement a conversational retrieval chain for the example of Wikipedia-based Q&A about nations at Uppsala University.
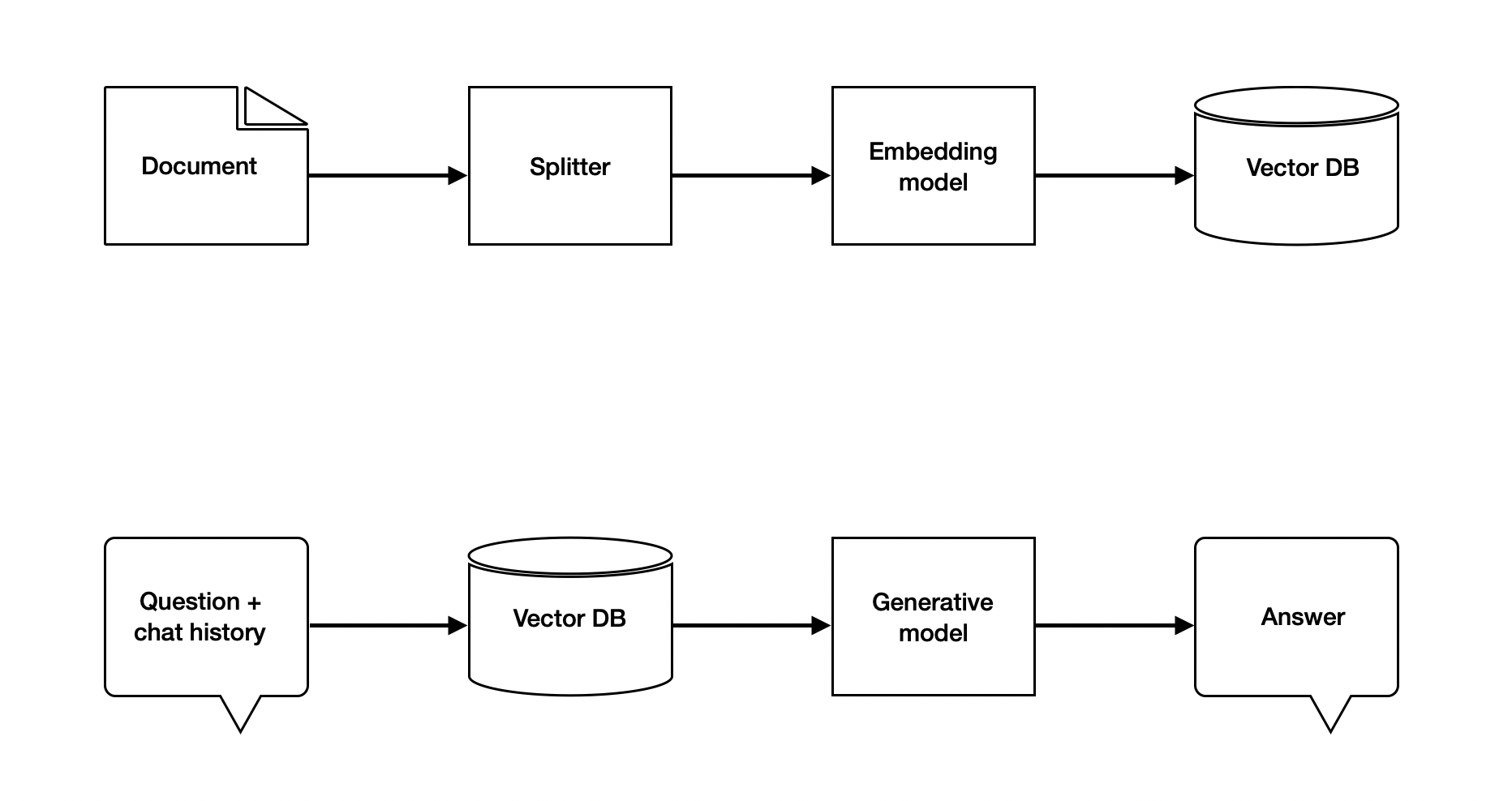
Step 1: Load and split documents
The first step is to load the source documents and split them into chunks with suitable chunks, such that the system can retrieve the most relevant information as the context of a prompt sent to a LLM.
The source documents can be almost anything: PDFs, webpages, PowerPoint presentations, or even source code as Python and Java files. LangChain integrate many document loaders for handling different data formats.
For our application, the source document is the Wikipage about UU (a HTML file). We could use the WebBaseLoader to load the document and then split the long document into chunks.
An alternative is to use HTMLHeaderTextSplitter and split text directly from a URL. We just need to specify which headers we want to use for splitting the HTML file.
from langchain_text_splitters import HTMLHeaderTextSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter
# The URL to the UU wikipage
url = "https://en.wikipedia.org/wiki/Uppsala_University"
# Specify which headers to split on
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
("h4", "Header 4"),
]
# Split html file based on the above headers
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
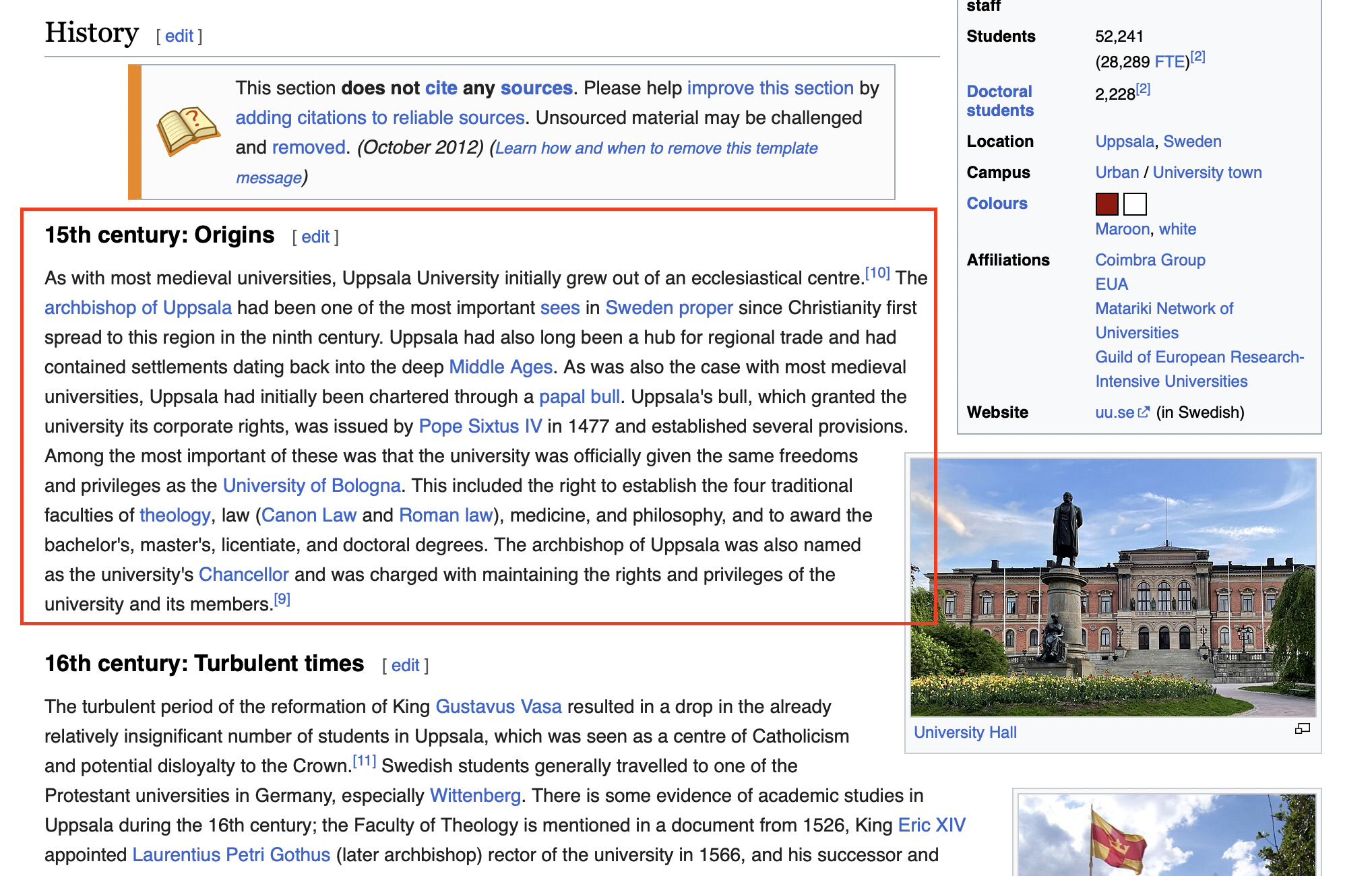
The result html_header_splits is a list of 41 documents where each document is basically a section of the UU’s Wikipage. For example, let’s print the 4th document in the list:
page_content=”As with most medieval universities, Uppsala University initially grew out of an ecclesiastical centre.[10] The archbishop of Uppsala had been one of the most important sees in Sweden proper since Christianity first spread to this region in the ninth century.
…
The archbishop of Uppsala was also named as the university’s Chancellor and was charged with maintaining the rights and privileges of the university and its members.[9]” metadata={‘Header 1’: ‘Uppsala University’, ‘Header 2’: ‘History[edit]’, ‘Header 3’: ‘15th century: Origins[edit]’}
which is exactly the level 3 section with the title “15th century: Origins”. See the screenshot below.
We can further split the HTML into smaller chunks by using RecursiveCharacterTextSplitter and control the chunk size. Sometimes smaller chunks can help a LLM to retrieve the most relevant info. But in this case, I find that using the header based chunks gives the best performance, while further splitting the HTML into smaller chunks actually confuse some LLMs. The less powerful ones such as Llama2 or GPT-3.5 seems to be more sensitive to the splitting strategy, which LLMs such as GPT-4 is more robust in terms of handling fragments of information. My interpretation is the following:
- By splitting the wikipage to the level 4 headers, each chunk already has a concentrated topic and a suitable size.
- Splitting a level 4 section into even smaller chunks (for example with
chunk_size = 500) could break the semantic structure of a section and spread a topic into different chunks. - Another practical consideration is that a more granular splitting strategy will consume more computation and storage resources.
To sum up, we want to split the document into a list of chunks where each chunk has a suitable size and is concentrated on a topic or a sub-topic. It is NOT always better to split documents into more granular pieces.
Step 2: Embedding and storing vectors
After splitting the document into suitable chunks, the next step is to embed them into vector representations and store those vectors in a database. For understanding what is text embedding and why we need this, please refer to the part two of this blog.
First thing first, we need to pick a LLM for embedding/querying texts and a LLM for the actual chat (generation). Please note that those LLMs do not have to be the same. We can use one LLM for embedding and another for chat.
If we use an open source model (Llama2) with Ollama running locally, here is the code:
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.llms import Ollama
# Define the embedding and chat models with Ollama
embeddings = OllamaEmbeddings(model="llama2")
llm = Ollama(model="llama2")
ALternatively, we could use OpenAI models via their APIs:
from dotenv import load_dotenv
import os
# I store the API keys in an .env file
load_dotenv()
# Access the OpenAI API key
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
# Define the embedding and chat models with OpenAI
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
llm = ChatOpenAI(model="gpt-3.5-turbo")
# llm = ChatOpenAI(model="gpt-4")
In the above, I use the text-embedding-ada-002 embedding model (the default model) for demonstration purposes. In January 2024, OpenAI released two new embedding models (text-embedding-3-small and text-embedding-3-large) which have better performance. Given the same embedding model, I will test the gpt-3.5-turbo and gpt-4 generation models later in the Q&A.
Next, we will embed the HTML splits into vectors and store them in a vector database. Today, there are many vector databases out there. Some popular ones include Pinecone, Milvus, MongoDB, Elasticsearch and Chroma. For this small example, we stick with the good old FAISS.
from langchain_community.vectorstores import FAISS
# Embedding HTML splits into vectors and store in the vector database
vector_db = FAISS.from_documents(html_header_splits, embeddings)
# FAISS and many other vector DB provide a method (as_retriever) for information retrieval.
retriever = vector_db.as_retriever()
There are a number of things we can tune in this step. For example, when initialize the FAISS object, we can change the distance_strategy (default is Euclidean distance). The as_retriever method can talso ake several optional parameters such as search_type (by similarity, max marginal relevance, or similarity score threshold). When use the default similarity search, we can also specify the k (default value 4) most similar documents to return.
There are enormous research and engineering efforts behind building a scalable, efficient, and accurate vector database for similarity search, which will not be covered in this blog.
Step 3: History aware retrieval
Now we have the document stored in a vector database and are ready to build the conversational Q&A app. This app needs to
- Be aware of the chat history;
- Retrieve relevant information as the context.
We first build a prompt to include the chat history and a retriever chain to generate the search query based on the latest question and chat history. In LangChain, a chat history is a list of HumanMessage and AIMessage. LangChain also has a retriever create_history_aware_retriever which use the LLM to generate a search query based on the chat history and the latest question and retrieve the most relevant document splits stored in the vector database.
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage
# Initialize the chat history as an empty list
chat_history = []
# Example prompt to generate a search query based on the chat history and the latest user question
prompt_search_query = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up in order to get information relevant to the conversation")
])
# Use the LLM to generate a search query and retrieve the most relevant documents
retriever_chain = create_history_aware_retriever(llm, retriever, prompt_search_query)
The above retriever chain will give us a list of relevant documents as the context for generating the answer. So the next step is to build a prompt to generate the answer and connect the retriever chain to the final retrieval chain:
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# Example prompt to generate an answer based on the context
prompt_answer = ChatPromptTemplate.from_messages([
("system", "Answer the user's quesitions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
])
# Use the LLM to generate the answer based on the context
document_chain = create_stuff_documents_chain(llm, prompt_answer)
retrieval_chain = create_retrieval_chain(retriever_chain, document_chain)
Step 4: Q&A and update chat history
Now we have the end-to-end conversational retrieval chain ready to be tested! We will ask three questions sequentially and update the chat history after each question.
The first question is “How many nations are there at Uppsala University?”:
human_input = "How many nations are there at Uppsala University?"
ai_msg = retrieval_chain.invoke({
"chat_history": chat_history,
"input": human_input})
print(ai_msg["answer"])
chat_history.extend([HumanMessage(content=human_input), AIMessage(content=ai_msg['answer'])])
The AI (Llama2) gives the following answer:
Based on the information provided in the text, there are 13 nations at Uppsala University. These include:
1. Stockholms nation
2. Uplands nation
3. Gästrike-Hälsinge nation
4. Östgöta nation
5. Västgöta nation
6. Södermanlands-Nerikes nation
7. Västmanlands-Dala nation
8. Smålands nation
9. Göteborgs nation
10. Kalmar nation
11. Värmlands nation
12. Norrlands nation
13. Gotlands nation
And the extended chat_history is now no longer an empty list but contains one human message and one AI message:
[HumanMessage(content='How many nations are there at Uppsala University?'),
AIMessage(content='Based on the information provided in the text, there are 13 nations at Uppsala University. These include:\n\n1. Stockholms nation\n2. Uplands nation\n3. Gästrike-Hälsinge nation\n4. Östgöta nation\n5. Västgöta nation\n6. Södermanlands-Nerikes nation\n7. Västmanlands-Dala nation\n8. Smålands nation\n9. Göteborgs nation\n10. Kalmar nation\n11. Värmlands nation\n12. Norrlands nation\n13. Gotlands nation')]
Comparing different LLMs
Next, we test 3 different LLMs (Llama2, GPT-3 Turbo, and GPT-4) and compare their behaviours through the above conversational Q&A example. We will ask three questions:
- Q1: How many nations are there at Uppsala University? (13)
- Q2: Is it mandatory to join a nation? (No)
- Q3: When did the compulsory membership end? (2010 July)
We start without RAG and test the LLMs on the first question.
| Llama2-7B | GPT-3 Turbo | GPT-4 | |
|---|---|---|---|
| Q1 | Uppsala University is a multi-national university, with students and staff from all over the world. While the exact number of nations represented at the university can vary depending on the academic year, I can provide you with some general information on the diversity of the student body at Uppsala University. According to the university’s website, international students make up around 20% of the student population. The largest groups of international students come from … | There are around 100 nations at Uppsala University. | There are 13 student nations at Uppsala University. |
We see both Llama2 and GPT-3 Turbo failed to answer the question correctly without RAG. Both LLMs interpreted “nations” as “countries” instead of student associations. On the other hand, GPT-4 gave the correct answer.
Now we apply RAG and see how each model answer the questions.
| Llama2-7B | GPT-3 Turbo | GPT-4 | |
|---|---|---|---|
| Q1 | Based on the information provided in the text, there are 13 nations at Uppsala University. These include: 1. Stockholms nation 2. Uplands nation 3. Gästrike-Hälsinge nation 4. Östgöta nation 5. Västgöta nation 6. Södermanlands-Nerikes nation 7. Västmanlands-Dala nation 8. Smålands nation 9. Göteborgs nation 10. Kalmar nation 11. Värmlands nation 12. Norrlands nation 13. Gotlands nation | There are currently thirteen nations at Uppsala University, but there used to be fourteen with the addition of Skånelandens nation. | There are thirteen traditional nations at Uppsala University. However, since the 1960s there was a fourteenth nation, the Skånelandens nation, which was made redundant in 2010. |
| Q2 | According to the text, joining a nation is not mandatory for students at Uppsala University. It states that “The traditional four-faculty organization of European universities has evolved into the present nine faculties” and “The disciplinary domains and their faculties are as depicted below,” without mentioning any requirement to join a nation. Therefore, it is not mandatory to join a nation at Uppsala University. | Until June 2010, students at Uppsala University were obliged to become members of one of the nations. However, membership in a nation ceased to be mandatory after that date. | No, it is not mandatory to join a nation. Up until June 2010, students at Uppsala University were obliged to join one of the nations. However, this requirement was abolished in 2010. |
| Q3 | The information provided in the text does not mention when the compulsory membership of nations ended at Uppsala University. In fact, the text does not provide any information on the topic of compulsory membership of nations at all. Therefore, I cannot answer this question based on the information provided. | The compulsory membership in a nation at Uppsala University ended on 1 July 2010. | The compulsory membership in a student union ended on 1 July 2010. |
We can make the following observations based on the above results:
- Llama2-7B is the smallest model among the three and perform the worst in this test. The LLM generates a perfect answer for Q1, a correct but confusing answer for Q2, and a wrong answer for Q3 (claim no info is provided in the text, which is wrong).
- GPT-3 Turbo answers all questions correctly. However, when I used a granular splitting strategy (
RecursiveCharacterTextSplitterwithchunk_size=500), it got some questions wrong. My understanding is that the granular splitting strategy spread the info about nations in several fragments, which posed challenges for GPT-3 Turbo to retrieve the most relevant info and use them as the context. - GPT-4 answers all questions correctly. In fact, GPT-4 almost answered all questions in the first answer, which makes question 2 and 3 redundant.
Conclusion
RAG is a super useful method to build LLM applications based on documented information. While it is not difficult to make a small example work, it can be challenging to implement RAG on a large amount of documents. It needs a lot of prompt engineering, good splitting strategy, efficient vector search, and reliable LLMs to produce reliable results.
References
[1] LangChain Cookbook: https://python.langchain.com/docs/expression_language/cookbook
[2] LangChain Document: https://api.python.langchain.com/en/latest/langchain_api_reference.html